

The Sorting Machine
Stray Narratives, Issue 01
There is an old joke amongst those of us who have spent too long in private banking. A client asks his banker what time it is. The banker takes the client’s watch, tells him it is half past three, charges him a fee, and keeps the watch. The reason this joke has survived decades of retelling is that it captures something true about the financial services industry in particular and the professional economy in general: a great deal of what passes for expertise is really the application of a client’s own information back to them, repackaged in a format they find more digestible. The banker does not know what time it is any better than the client. He simply has the confidence, the suit, and the institutional authority to deliver the answer.
I begin with this image because I believe it captures something essential, and almost entirely overlooked, about artificial intelligence. The public discourse around AI has become trapped between two extremes. On one side, the evangelists describe a technology so powerful it amounts to a new form of intelligence, one that will reshape civilisation within a decade. On the other, the sceptics insist it is nothing more than an elaborate statistical trick, a party game dressed in a lab coat. The truth, as is so often the case with emotive subjects, lies in neither camp. But more importantly, the argument itself is a distraction. By mixing the philosophical question of whether AI is truly intelligent with the economic question of what it will actually do to work and markets, we end up understanding neither.
This first issue of Stray Narratives is an attempt to separate those two questions and then pursue the economic one with some rigour. I intend to lay down a few foundations: what AI actually is, what it does well, what it cannot do, and where its boundaries lie, so that in future issues we can build on them. There will be no trade ideas here, no market calls, no forecasts. Just a framework. The reader will have to trust me that the framework is worth the patience, because the conclusions it eventually leads to are, I believe, both surprising and consequential.
Let me start with a simple observation that I think clarifies a great deal.
The internet, when it arrived in the early 1990s, organised access. Before the web, information existed in libraries, in proprietary databases, in the filing cabinets of institutions. The internet did not create new information. It made existing information accessible to anyone with a connection. This was transformative, but the transformation was about distribution, not about the information itself.
But access brought its own problem, and it is one that rarely receives the attention it deserves. By democratising the ability to publish, the internet did not merely make existing high-quality information available to all. It simultaneously unleashed an explosion of new content of wildly uneven quality. Blogs, forums, opinion pieces dressed as analysis, marketing copy masquerading as research, and an entire industry of search-engine-optimised noise flooded the same channels through which genuine expertise was now flowing. The irony is considerable: the same technology that gave every individual access to the world’s best thinking also buried that thinking under an avalanche of the world’s worst. For the first time in history, the problem was not that people lacked information. It was that they had too much of it and no reliable way to separate the signal from the noise.
I should declare a bias here. I have always congratulated myself on never having invested the time to master any particular technology, on the grounds that it will be obsolete by the time I have. This has proven to be one of my more reliable analytical frameworks. But even from the comfortable distance of a man who has never fully understood how any of it works, the pattern is clear.
Search engines, when they matured a decade later, organised retrieval. The internet had by then created such a vast, unstructured mass of accessible information that finding anything useful within it had become its own problem. Google and its peers solved this partially by ranking and filtering, not by creating new knowledge but by making existing knowledge findable. Partially, because as anyone who has tried to research a medical symptom or compare financial products online can attest, the ranking algorithms themselves became susceptible to manipulation. The noise did not disappear. It learned to game the system.
Large language models, the technology at the heart of what we call AI, organise synthesis. They take the vast body of human knowledge that the internet made accessible and search engines made retrievable, and they recombine it. They can summarise a thousand-page report, translate a technical paper into plain language, draft a legal brief in the style of any firm you choose, or identify patterns across datasets that no human could hold in working memory simultaneously. This is genuinely impressive. It is also, if one is honest about it, the logical next step in a progression that has been underway since the mid-1990s. The internet made it possible to find a needle in a haystack. Search engines made it possible to find the right needle. Large language models make it possible to melt down all the needles and reforge them into something new. But the haystack was always the same haystack. The raw material, the accumulated written output of human civilisation, has not changed. What has changed is the sophistication with which it can be reorganised.
This is the third act of a single play, not the opening night of a new one.
I labour this genealogy because it matters enormously for how we think about the economic implications. If AI is the natural continuation of a thirty-year arc, from access to retrieval to synthesis, then the right framework for understanding its impact is evolutionary, not revolutionary. The technology is real and powerful. The hype, however, borrows the language of revolution, and revolutions create very different market structures from evolutions. The distinction between the two will, I suspect, turn out to be one of the most consequential analytical choices an investor can make over the coming years. But I am getting ahead of myself. More on this in future issues.
Now, a brief word on the philosophical question, if only to set it aside properly. The debate over whether AI can truly “think” has generated enormous heat and remarkably little light. Howard Marks of Oaktree Capital, in his recent memo AI Hurtles Ahead (February 2026), illustrates the problem with admirable transparency.[1] He asks an AI model to explain itself, and the model does so with charm, personalised references, and a convincing simulacrum of intellectual humility. Marks is suitably impressed. The model even mounts a spirited defence of its own cognitive abilities by pointing out, quite correctly, that all human learning also consists of absorbing patterns from others and recombining them.
It is a clever argument. It is also, in the context of what matters for investors, almost entirely beside the point.
Whether AI’s process constitutes genuine thought or extraordinarily sophisticated pattern matching is a question for philosophers and cognitive scientists. For those of us concerned with capital allocation, the relevant question is purely functional: what can it do, and what can it not do? The model itself, in a moment of commendable honesty, provided the answer. The economic question, it said, is not whether AI truly understands. The economic question is whether AI does the work.
On that formulation, I agree entirely. But I would add a qualification the model did not volunteer: the economic question also depends on which work. And it is here that the current consensus, in my view, makes its most significant error.
Consider a game of chess. There is a board, there are rules, there are two players, and at the end there is a winner. The outcome is verifiable. You can look at the board and determine, with certainty, which side has won. There is no room for interpretation, no scope for negotiation, and no possibility that the answer depends on the institutional context in which the game was played.
Now consider a task that those of us in private banking know intimately: the review of a client’s investment mandate. Part of this work is verifiable. The performance attribution can be checked, the fee calculations can be audited, the compliance with investment guidelines can be confirmed against the mandate document. AI can do all of this, and it can do it faster and more accurately than any team of analysts I have ever managed. But the mandate review does not end there. The actual recommendation, which manager to retain and which to replace, how to rebalance the allocation across asset classes, and above all how to navigate the competing interests of a family whose different generations have fundamentally different risk appetites, time horizons, and views on wealth preservation, that is an entirely different exercise. There is no correct answer to be looked up. There is no dataset that resolves the tension between a patriarch who wants capital preservation and his daughter who wants impact investing. There are only positions, relationships, and the slow accumulation of trust that allows a banker to say, in a room full of family members who disagree, “I think we should do this,” and be heard.
This distinction, between tasks that have a verifiable correct answer and tasks that do not, is, I believe, the single most important analytical tool for understanding AI’s economic impact. AI is extraordinarily good at the first category. It can verify facts, check calculations, compare documents, identify inconsistencies, summarise positions, and flag anomalies with a speed and thoroughness that no human team can match. It is, in short, a magnificent sorting machine.
But the second category, the contested, the negotiated, the coordinative, is a different matter entirely. Enterprise software, for example, is routinely described as a tool for performing cognitive work. It is not. As Andrea Pignataro argues persuasively, it is a tool for coordinating cognitive work among many agents with different information, different incentives, and different levels of authority, all operating under incomplete trust.[2] When a large institution adopts a system to manage its workflows, it is not primarily seeking a smarter employee. It is seeking a common grammar, a set of agreed protocols that allow hundreds or thousands of people to work together without constantly renegotiating the terms of their interaction. Organisations do not merely use their systems. Over time, they come to speak them. The data models, the process flows, the reporting standards, the permissions architectures: these are not cognitive tools. They are institutional artifacts. They are the grammar of organisational life.
The distinction matters because AI’s capacity to perform a task, even to perform it brilliantly, does not automatically translate into the ability to coordinate that task across an institution. Pignataro calls this the substitution fallacy: the conflation of a task with a system.[2] A new hire who produces a better analysis than anyone in the department does not thereby eliminate the need for the department’s templates, its approval workflows, its reporting hierarchies, or its compliance protocols. The templates are not there because previous analysts were incompetent. They are there because the institution needs a common language, and a common language is not the same thing as a correct answer.
I propose, therefore, a simple taxonomy. Where work involves cognitive vulnerability, that is, where the quality of the outcome depends primarily on the cognitive ability of the individual performing it, AI represents a direct and immediate threat. A research associate who summarises earnings reports, a junior lawyer who reviews contracts for standard clauses, an insurance underwriter who assesses routine applications against a fixed set of criteria: these roles are cognitively vulnerable because the task has a broadly verifiable outcome and AI can reach that outcome faster and more cheaply.
Where work involves institutional resilience, that is, where the outcome depends on coordination among multiple agents operating under different incentives and incomplete information, the picture is entirely different. Not because AI is incapable, but because the barrier to adoption is not capability. It is the institutional fabric itself: the regulatory frameworks, the entrenched process architectures, the labour protections, the sheer accumulated weight of organisational custom. These structures are slow to change not because the people within them are slow, but because the structures serve a function. They are the coordination mechanisms that allow complex institutions to operate without constant renegotiation. Replacing them requires not a better tool but a different institutional grammar, and grammars do not change on the timescale of a product cycle.
There are two additional dimensions to this institutional inertia that I think are under appreciated. The first is trust. Not trust in the abstract, but the specific, relational, accumulated trust between agents within an institution: between a portfolio manager and a risk officer, between a deal team and a credit committee, between a regulator and the compliance function. This trust is not informational. It is built through repeated interaction, through shared experience of how individuals behave under pressure, and through the reputational stakes that come with being known within a professional community. It is not transferable to a model, however capable, and its absence in any decision chain introduces a friction that no amount of analytical horsepower can overcome.
The second is legal liability. When a decision goes wrong, and in finance decisions go wrong with reliable regularity, someone must be accountable. The existing legal and regulatory architecture is built entirely around human agency: a named individual made a decision, and that individual (and the institution they represent) bears the consequences. Delegating a judgment call to an AI agent does not eliminate the liability. It makes it harder to assign. Who is responsible when an AI-generated recommendation leads to a loss? The developer of the model? The institution that deployed it? The individual who approved the deployment? Until the legal frameworks provide clear answers to these questions, and there is no indication that they are close to doing so, this ambiguity alone constitutes a powerful brake on institutional adoption, one that has nothing whatsoever to do with the capability of the technology.
The failure to distinguish between cognitive vulnerability and institutional resilience is, in my view, the source of the most common analytical errors being made about AI today. The market appears to be pricing AI as a capability story: the more capable the models become, the more work they will absorb, the more value they will create. But much of economic life is a coordination story, and coordination runs on structures that are resistant to disruption precisely because they are not primarily about capability.
With these foundations in place, I want to conduct a thought experiment. Not about the corporate world, that is a more complex story involving all the institutional resilience I have just described, and I shall address it in a future issue. Instead, I want to think about what happens when AI is deployed not by institutions but by individuals.
The private consumer faces none of the barriers that slow institutional adoption. There is no compliance department, no procurement cycle, no legacy system, no labour agreement. The individual simply downloads an application and begins using it. And the question that interests me is this: what happens when that application is a tireless, cost-free optimisation engine working exclusively on behalf of a single consumer?
Consider the following scenarios, all of which are either already possible or will be within a very short time. A consumer looking for a holiday faces an enormous search problem: thousands of destinations, tens of thousands of hotels, countless combinations of flights and transfers, and a pricing structure so deliberately opaque that the airlines themselves likely struggle to explain it. Most consumers solve this through “satisficing”, they find something good enough and book it. The gap between the choice they make and the optimal choice is often substantial, but the cost of closing that gap is prohibitive. Now give that consumer an AI agent. Not a chatbot that answers questions, but an autonomous agent that searches every provider, compares every combination, and identifies the optimal price-quality trade-off for that specific consumer’s preferences. The search cost drops to approximately zero.
Now apply the same logic to insurance. The average consumer purchasing home or motor insurance faces a comparison problem of staggering complexity. Policies differ across dozens of dimensions: deductibles, exclusions, claims processes, renewal terms. The industry has spent decades making those differences difficult to compare. Comparison websites helped, but they operate within the constraints of their commercial relationships and their own incentive structures. An AI agent working exclusively on behalf of the consumer, with the capacity to read and compare full policy documents, to identify exclusions buried in clause 14(b), to cross-reference claims satisfaction data with pricing, that agent fundamentally alters the competitive dynamics of the industry. The opacity that currently supports pricing power across the sector becomes a vulnerability.
Or consider the supplements and health products that represent a substantial and growing market built, in many cases, on remarkably thin scientific evidence. I can speak to this from personal experience. I recently asked an AI agent to review the clinical evidence for the supplements I take each morning. The answer arrived with the gentle diplomacy of a doctor delivering bad news: most of what I have been swallowing with such conviction has approximately the same evidentiary support as my belief that I understand how the internet works. The point is not that these products are fraudulent, many are simply unproven. The point is that the consumer, for the first time, has the analytical resources to distinguish between what is proven and what is merely marketed.
In each of these cases, the same dynamic is at work. An enormous amount of economic activity exists today because consumers lack the time, the data, or the analytical capacity to identify the optimal choice. This is not a criticism of consumers. The search costs are genuinely prohibitive, and satisficing is a perfectly rational response to limited resources. But AI removes the constraint. When every consumer has access to a tireless verification engine, the information asymmetry that supports vast swathes of the service economy ceases to exist.
The implications depend, however, on two variables, not one. The first is the verifiability of the value proposition: can the quality of this product or service be objectively measured and compared before purchase? The second is the substitutability of the provider: if a consumer identifies a better alternative, how easily can they switch? Verifiability alone is not sufficient for the concentration dynamic I am describing. A parent might know perfectly well that one school produces better outcomes than another, but if they cannot move house, the knowledge does not translate into market pressure. The interplay between these two dimensions produces four distinct outcomes, and I think each one tells a genuinely different story about what AI does to demand.
Where verifiability is high and switching costs are low, you have the kill zone. Insurance, commodity financial products, travel, consumer electronics, standardised services: any market where the consumer can compare and switch freely. AI-driven consumer optimisation hits these sectors hardest. The best provider in each category captures a disproportionate share, and everyone else competes for the remainder under intense margin pressure. This is winner-take-most economics applied not to a single industry but to every consumer-facing market where quality and price can be objectively measured.
Where verifiability is high but switching costs are also high, the dynamics are different and, I believe, more politically consequential. Healthcare, education, public services: the consumer can now see that a better alternative exists but cannot easily access it. I should be honest here, much of the data that would be needed to make such comparisons rigorously does not yet exist in comparable form. But this may be precisely the point. The pressure AI creates may be less about analysing data that already exists and more about demanding that such data be produced. A parent who knows that an AI agent could compare schools, if only the outcomes data were published, becomes a parent who demands transparency. A patient who understands their choice of specialist could be informed by outcome data becomes a voter who insists on it. The concentration here does not happen through market switching. It happens through political mobilisation: demands for choice, for transparency, for accountability. This is where AI’s impact collides most directly with institutional rigidity, and the result is not market disruption but political disruption.
Where verifiability is low and switching costs are also low, you have the taste economy. Restaurants, fashion, art, entertainment, bespoke personal services. AI cannot sort these because there is no objective metric to optimise against. But this territory may become more valuable precisely because it cannot be compressed. As margins collapse in the verifiable economy, both consumers and businesses may migrate toward the unverifiable as the remaining source of differentiation and pricing power. I shall have much more to say about this in the next issue, because I believe it holds the key to understanding where economic value goes when the verifiable half of the economy compresses.
Where verifiability is low and switching costs are high, you have the trust and relationship economy. Private banking (the real kind, not the commoditised version), long-term advisory relationships, family office governance, complex institutional partnerships. The value proposition cannot be objectively compared, and the cost of switching, in terms of lost trust, institutional knowledge, and relationship capital, is prohibitive. This is the most resilient quadrant, and it maps directly onto the institutional resilience I described earlier.
I want to be careful here. I am not predicting the collapse of any particular industry or the failure of any particular business model. I am doing something more modest: identifying a structural force and noting that it points in a direction the consensus has not, to my knowledge, seriously considered. The mainstream discussion of AI’s economic impact focuses almost exclusively on the supply side, on jobs replaced, on productivity gained, on costs reduced within the enterprise. The demand-side story, what happens when the consumer becomes an optimising agent, is at least as important and has received a fraction of the attention.
I have spent this first issue laying down what I hope are useful foundations. AI is the third act of a thirty-year information arc, not a new play. Its power lies in synthesis and verification, and it is formidable within those boundaries. But its boundaries are real: the gap between verifiable tasks and contested ones, between cognitive capability and institutional coordination, between what a technology can do and what the structures of economic life will allow it to do. And those structures are reinforced by forces, trust between agents, legal liability, regulatory architecture, that have nothing to do with the technology’s capability and everything to do with the institutional fabric through which economic life is conducted. These distinctions are not minor qualifications. They are the essential framework for understanding what comes next.
I have also conducted a thought experiment about what happens when that verification power is placed in the hands of every individual consumer. The conclusion is not uniform. Where consumers can both verify and switch, concentration toward best-in-class providers will be severe. Where they can verify but not switch, the pressure becomes political. Where verification itself is impossible, because the value lies in taste, trust, or judgment, the dynamics are different entirely, and that territory may become the most valuable of all.
But there is a mirror image to this thought experiment that I have deliberately left for a future issue. If everything that can be verified collapses to zero margin, then the scarce resource in the economy shifts entirely to the unverifiable: to judgment, to negotiation, to coordination under incomplete trust, to all the things that do not have a correct answer that an algorithm can identify. What happens to that contested ground? What does it look like when the verifiable half of the economy compresses and the unverifiable half becomes the only source of pricing power? I believe the market may be pricing the wrong side of this equation, and I intend to explore why.
I have deliberately begun with the impact on private users rather than on institutions because adoption at the individual level faces the fewest barriers. The individual consumer answers to no one but themselves. They have no compliance department, no procurement cycle, no legacy architecture. The institutional world, with its regulatory frameworks, its entrenched coordination structures, its labour protections, its sheer organisational inertia, will move more slowly, and the effects will be more complex. But they will not be smaller. If anything, the coordination structures that make institutions slow to adopt AI are the very structures that make institutional disruption, when it eventually comes, far more consequential. That, too, will be the subject of a future issue.
For now, I leave the reader with a single question to consider. It is the question that, in my view, matters more than any other for understanding the economic impact of AI, and it is one I have not seen asked in any of the widely circulated investment memos on the subject: What happens when everything that can be verified is known equally by all?
The Stray Narratives Framework: A Quick Reference
I. AI’s Impact on Work: Cognitive Vulnerability vs. Institutional Resilience

II. AI’s Impact on Demand: The Verification-Substitution Matrix
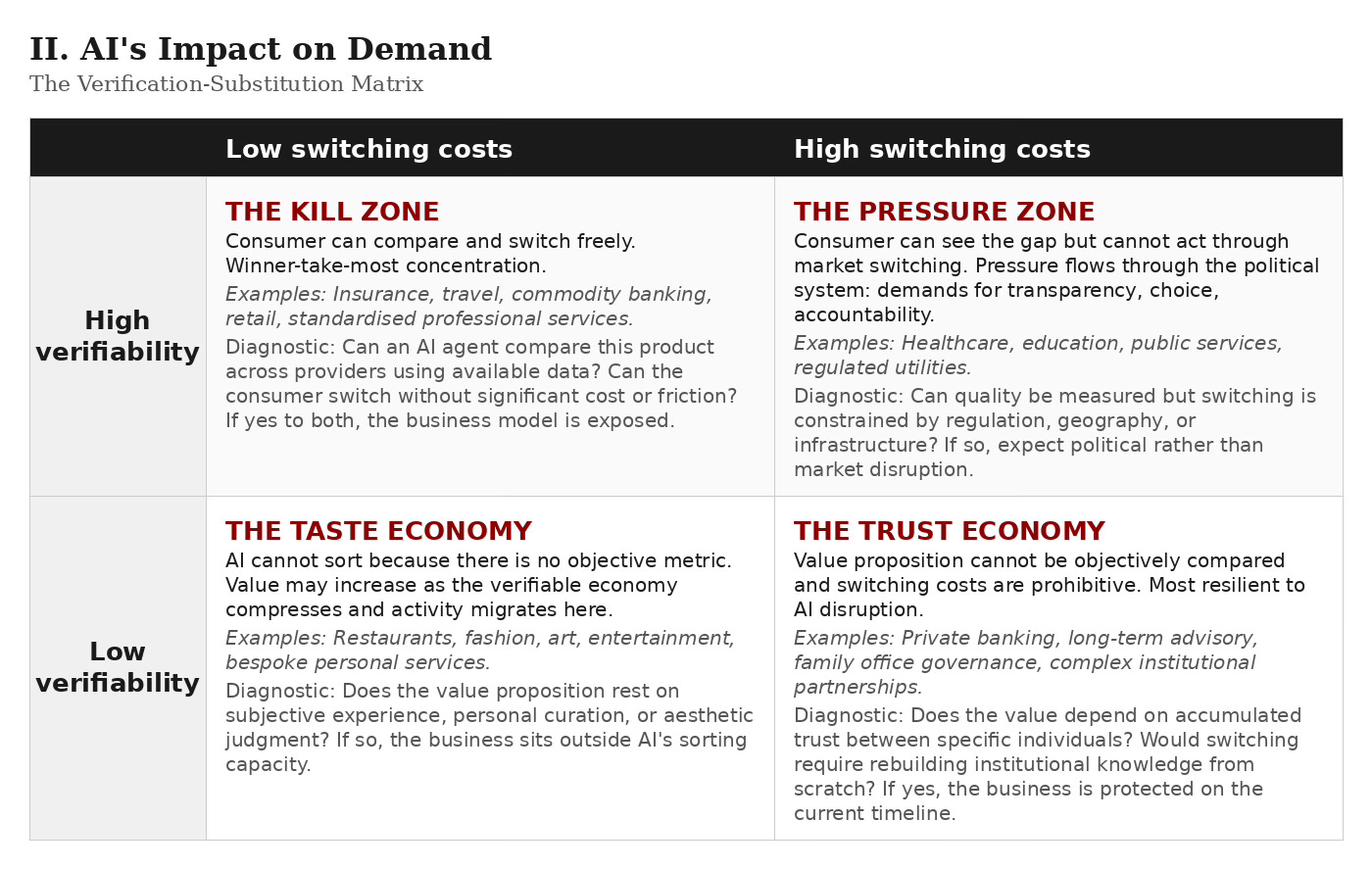
Diagnostic questions for each quadrant:
Kill Zone: Can an AI agent compare this product across providers using available data? Can the consumer switch without significant cost or friction? If yes to both, the business model is exposed.
Pressure Zone: Can quality be measured but switching is constrained by regulation, geography, or infrastructure? If so, expect political rather than market disruption: demands for published data, consumer choice, and institutional reform.
Taste Economy: Does the value proposition rest on subjective experience, personal curation, or aesthetic judgment? If so, the business sits outside AI’s sorting capacity, and may benefit as the verifiable economy compresses.
Trust Economy: Does the value depend on accumulated trust between specific individuals? Would switching require rebuilding institutional knowledge from scratch? If yes, the business is protected on the current timeline.
References
[1] Howard Marks, AI Hurtles Ahead, Oaktree Capital Management memo, February 26, 2026.
[2] Andrea Pignataro, The Wrong Apocalypse. The arguments on enterprise software as coordination grammar, the substitution fallacy, and the distinction between tasks and language games draw extensively on this essay. Pignataro’s framework, which builds on Wittgenstein’s concept of language games to describe how organisations do not merely use their software but come to speak it, is in my view one of the most penetrating analyses of AI’s institutional limits published to date.
[3] The distinction between verifiable tasks and contested ones, and in particular the observation that making verifiable work cheaper causes more contested work to appear, is informed by Henry Gladwyn’s essay Contested Ground. His account of professional work as negotiation in contested space, rather than problem-solving with verifiable outcomes, underpins much of the taxonomy presented here.
[4] The genealogy of the internet as a three-stage arc (access, retrieval, synthesis) and the argument that AI represents a technology shift absorbed by incumbents rather than a platform shift creating new distribution, draws on work by Sameer Singh, in particular AI is a Technology Shift, not a Platform Shift. This framework will be explored in greater depth in the next issue.
Stray Narratives is published when the market demands a closer look. The next issue will explore the other side of the verification equation: what happens to contested ground when verifiable work becomes free.