

What We Got Wrong About the Internet (and May Get Wrong Again)
Stray Narratives, Issue 10
Key Takeaways
The historical record on technology shocks shows a recurring pattern: the first-order impact people argue about turns out to be smaller than the second-order impact almost nobody saw coming.
Three precedents (the talkies of 1930, the IT consensus of 1973, and the internet of 1995) all show the pattern, and the AI debate of 2026 already has the look of a fourth iteration.
Issue 06 The Noise Economy introduced friction elimination as one form of unforeseen second-order effect; this issue argues that noise itself, the recursive proliferation of AI-generated outputs, is plausibly another, and there will be more.
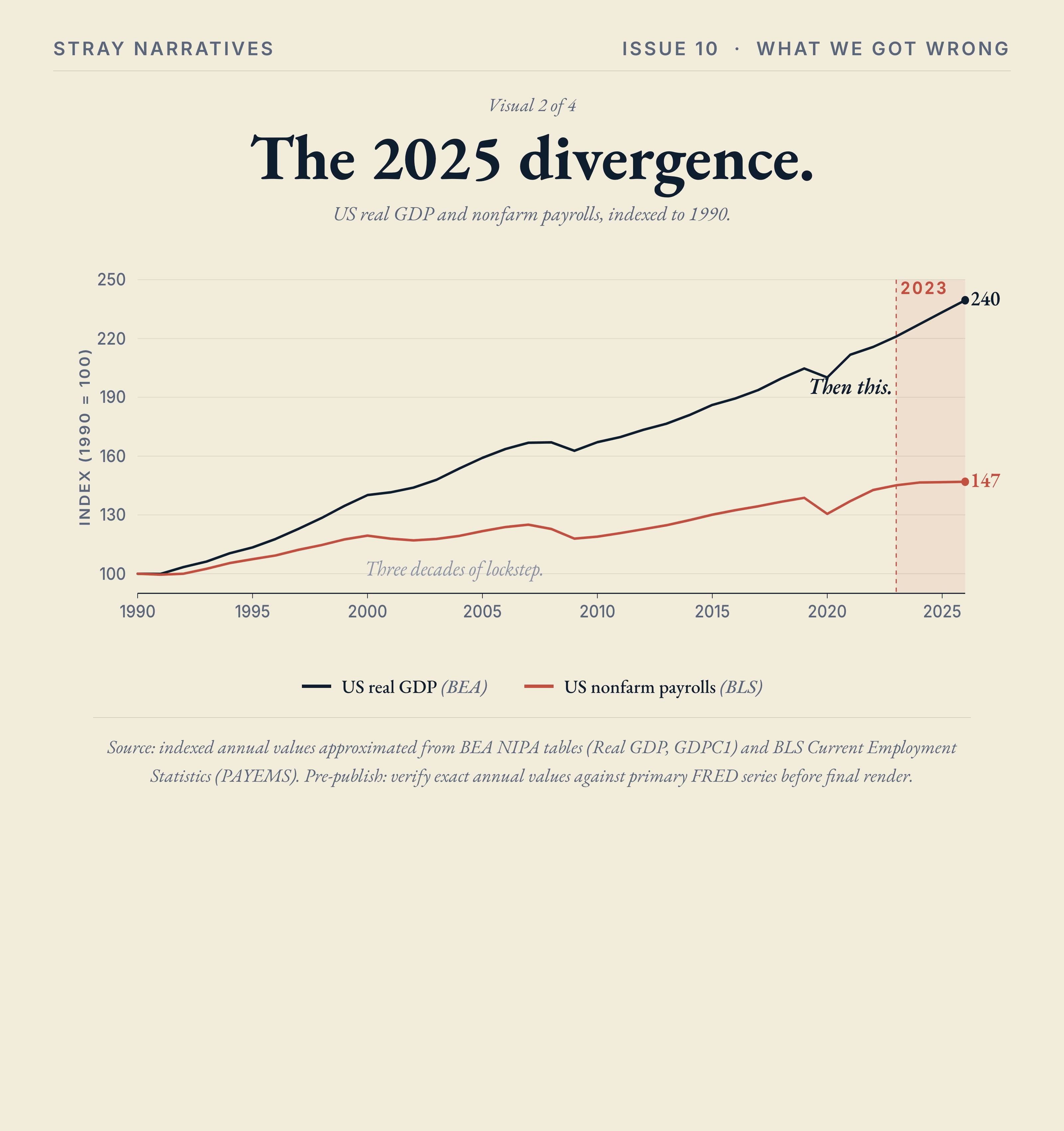
The contemporary anchor is the 2025 divergence: US GDP grew 2.2% with only 181,000 jobs added all year, the worst figure for any non-recession year of expansion since 2003, and Anthropic in 2026 is producing nearly the same revenue as Salesforce did in 2024 with around five per cent of the headcount.
The political response is already visible in New York’s vote for Mamdani, where voters experienced the divergence directly: GDP rising, markets soaring, material lives stuck.
Here below is a podcast version of this article produced with Notebook LLM, hope you enjoy it!
Twenty-four thousand musicians
In 1927, The Jazz Singer arrived in cinemas and the live-music industry began to evaporate. Roughly twenty-four thousand musicians worked in theatres across the United States and Canada at the time, accompanying silent films night after night with whatever combination of piano, violin, drums, and brass the local theatre could afford. By 1930, the American Federation of Musicians estimated that around twenty-two thousand of those jobs had vanished [1]. Almost the entire trade, in three years. In some markets the destruction was even faster: New York and Cincinnati both lost between half and three-quarters of their working musicians inside the first two years of sound.
They did not go quietly. In 1930 the American Federation of Musicians spent the equivalent of ten million dollars (in today’s money) on a national campaign begging audiences to refuse “canned music” and to keep going to theatres that still employed live performers. Joseph N. Weber, the union’s president, predicted that the public would never accept “like-less, soulless, synthetic music.” Edward More, music critic of the Chicago Herald Tribune, agreed: the films, he said, “have a long way to go before they can duplicate living musicians.” The whole defence rested on a single load-bearing assumption, which is that the new technology would have to match the old one to displace it. The films had to play violin.
They never did. The films did not have to. As Dror Poleg put it in his essay on this episode, disruptive technology rarely seeks to replicate. It sidesteps and makes the old standards redundant [2]. Recorded sound made music cheap and accessible to a vastly larger audience, and most of that larger audience turned out to be perfectly content with what Weber had dismissed as soulless. Weber was, in a narrow sense, proved right: the public never did warm to soulless synthetic music. They simply turned out to be indifferent to the difference, which proved entirely sufficient. The threat to the trade was never a robot violinist. It was a different technology entirely, one that bypassed the contest the musicians thought they were in.
The same script ran a generation later in print encyclopedias. Britannica had been the authoritative reference work for two hundred and forty-four years when, in 1993, Microsoft launched Encarta, a digital encyclopedia replicating Britannica with multimedia and a CD-ROM price point. The threat looked clear, and the threat was the wrong one. Eight years on, when the actual challenger arrived, it was Wikipedia: free, crowd-sourced, infinitely updatable, and not trying to be Britannica at all. Encarta died in 2009. Britannica stopped its print edition in 2012. The threat to two and a half centuries of authoritative reference publishing came from a different category of object entirely, one that had no interest in being authoritative in the old sense.
This is the pattern of unforeseen second-order effects, and the reason the talkie episode and the encyclopedia episode keep repeating themselves in the historical record is that they are a feature of how technological transitions actually work, not a one-off. A useful shorthand for what’s happening: call X the predicted impact of a new technology, the thing the consensus debate of the time fixates on; call Y the actual dominant impact, the thing that turns out to matter most in retrospect. For the talkies of 1930, X was “machines that play music well enough to replace the live ones” (which never had to come), and Y was “recorded sound, sidestepping live performance entirely.” X and Y rarely coincide. Y is usually bigger. And Y is almost always something nobody at the time of X was writing about. The argument that follows is that we are now in the next iteration of the same pattern, with AI in 2026 standing in for the talkies in 1927, and the internet in 1995 standing in as the most recent precedent of how badly the X-versus-Y misalignment can go.

The 1973 mirror
Forty-three years later, the consensus was the symmetric opposite, and it was wrong in the same way.
Hobijn and Jovanovic, in their 2000 paper on the IT revolution and the stock market, record the 1973 expectation as a stylised assumption in their model: information technology, the consensus held, would substitute for white-collar cognitive labour the way mechanisation had substituted for blue-collar physical labour [3]. The subsequent record inverted it. IT complemented cognitive workers rather than displacing them; the cognitive-skill premium widened through the 1980s and 1990s; the wage gini diverged. The bigger story, the one nobody was writing about in 1973, turned out to be the personal computer, the web, social media, the attention economy, the wholesale reorganisation of how information moves through a society. The first-order story (white-collar substitution) was the consensus debate. The second-order story (the reshaping of attention itself) was the one that mattered, and it was almost entirely unforeseen.
This is the pattern of unforeseen second-order effects, and the reason the talkie episode and the encyclopedia episode keep repeating themselves in the historical record is that they are a feature of how technological transitions actually work, not a one-off. A useful shorthand for what’s happening: call X the predicted impact of a new technology, the thing the consensus debate of the time fixates on; call Y the actual dominant impact, the thing that turns out to matter most in retrospect. For the talkies of 1930, X was “machines that play music well enough to replace the live ones” (which never had to come), and Y was “recorded sound, sidestepping live performance entirely.” X and Y rarely coincide. Y is usually bigger. And Y is almost always something nobody at the time of X was writing about. The argument that follows is that we are now in the next iteration of the same pattern, with AI in 2026 standing in for the talkies in 1927, and the internet in 1995 standing in as the most recent precedent of how badly the X-versus-Y misalignment can go.
A note on what Hobijn and Jovanovic actually do here. Their paper records the 1973 expectation as an empirical fact about what the consensus of the time held. The point of citing them is the observation that the consensus of the time was directionally wrong, and that being directionally wrong about a technology shock has been the historical baseline.
The scope, and what Issue 06 already mapped
A scope limit before going further, because the temptation to over-extrapolate from one’s own corner of the economy is almost the defining vice of writing about AI from inside the knowledge professions.
Issue 06 The Noise Economy established the relevant numbers [9]. Around thirteen per cent of the US workforce sits in roles with high friction-elimination exposure, the proceduralised cognitive layer that the AI debate fixates on. Seventy-seven per cent sits outside that frame entirely: food service, retail, manufacturing, transport, healthcare support, government, education. The mechanisms I’ll develop below are about the knowledge economy. Many sectors will be little affected by what feels, from inside the affected slice, like a massive threatening revolution. I’m inside that slice. You probably are too. That fact, on its own, ought to make both of us a degree more cautious about the breadth of any claim that follows.
Issue 06 also did half the analytical work this issue extends. Friction elimination was the argument that a whole layer of professional activity exists not because it creates value at the point of transaction but because it navigates an opacity AI is now liquidating. Take the opacity away and the activity disappears, with no displaced worker because there was nothing left to displace. Noise, the candidate this issue offers, is a different mechanism in the same family: friction elimination removes activity; noise multiplies it. Both are shapes of unforeseen second-order effect, both bypass the displacement debate, and both belong to the same affected slice. The working assumption is that there are more shapes still ahead.
The unforeseen Y, applied to AI
The first-order story for AI is the displacement-at-speed-X debate that fills the column inches. Will agents replace lawyers in three years or fifteen? How many call-centre seats will be gone by 2027? The debate is real, the numbers matter, and Issues 01 through 06 of this series have been engaged in it. The question this piece sets down is whether, as in 1930 and 1973, the dominant effect turns out to be something quite different and quite a lot bigger.
The candidate this issue offers is noise, and the closest precedent for what noise actually does to a working life is something every reader has lived with for thirty years.
Email is the precedent. Email was sold as a productivity tool, and it was a productivity tool, for a few months. Then the volume became unconstrained. Anyone could send anyone a message at zero marginal cost, and the cost of that asymmetry has accumulated into a working day in which knowledge workers spend a third or more of their hours triaging messages they did not ask for. Email did not replicate paper memos; it made the entire structure of paper-memo norms obsolete. The unforeseen Y of email, in 1995, was not the productivity gain we expected. It was the productivity tax we now live with. AI noise is the next iteration of the same dynamic, run at a generation’s worth of speed.
A few mechanisms underneath that label, observable now:
Recursive output proliferation. AI outputs become inputs become outputs. The half-life of any specific knowledge advantage collapses, because what one analyst learns this quarter is in everybody’s training set the next. The premium on having access to a piece of analysis falls because the cost of producing equivalent analysis falls. There is a great deal more of everything, and a great deal less to distinguish any one piece from any other. The shape of the resulting market is one in which volume rises and average per-unit value falls, perhaps a long way.
Constant experimentation as time-sink. Every team running parallel trials on tools, workflows, agents, and models. Time spent evaluating what to use displaces time spent on the work itself. There is a tax on attention that takes the form of having to keep up with the platform churn, and the tax compounds quietly because the comparison to the prior tooling regime fades from memory. People remember being busy; they do not always remember whether the busyness was productive.
Verification burden. When an AI can produce anything, verifying becomes the bottleneck. Citations may be hallucinated, code may compile and still be wrong, drafts may pass spell-check and still be incoherent on a re-read. Concrete cases are now a regular feature of professional practice. Lawyers in Texas, New York, and California have been sanctioned in the past eighteen months for filing briefs containing AI-fabricated citations, including, in one case, a complete fictitious appellate decision the firm had not noticed before submission. Federal judges now routinely spend several paragraphs of their sanction orders explaining, for the benefit of the bar, that the cited authorities do not exist, a sentence that until 2023 would have been a parody of itself. Software teams report a steady stream of AI-generated code that compiles and ships and is later discovered to have invented an API call that does not exist or a function whose stated behaviour does not match its actual logic. Hiring managers describe an arms race of AI-generated CVs and cover letters tuned to defeat applicant-tracking systems, where the marginal cost of producing an apparently-qualified candidate has fallen close to zero. In each case, signal-discrimination becomes the scarce capability, and it is exactly the capability that was previously externalised onto the production process: the editor, the legal reviewer, the senior analyst whose job was to know which numbers to trust. Strip out the production friction and the verification cost shifts up the chain, where it is harder and more expensive to apply at scale.
Attention fragmentation. Email becomes agent-to-agent. Search becomes AI-mediated. Content becomes infinite. The bottleneck is no longer capability but choice: what to attend to, in a stream that has lost most of the curatorial gates that used to do that work for us.
The recent precedent for what this dynamic does at cultural scale is social media, and the version of that precedent worth getting right is one the consensus often blurs. Social media as a mass cultural phenomenon was not, on its own, an internet story. The internet was the substrate. The carrier turned out to be the iPhone, twelve years later: a device nobody in 1995 had thought about, which made always-on access universal and turned social media from a niche curiosity into the dominant capture mechanism for human attention. The unforeseen Y, in retrospect, was the smartphone, not the internet. AI’s equivalent carrier is not yet named.
What the four mechanisms above describe is what current AI noise looks like in working life. They are diagnostic, not prophetic. The harder claim, and the one this piece commits to, is that the cultural and economic centre of gravity of the AI era will form somewhere none of the four mechanisms describes.
The pattern of which technologies actually scale into mass cultural phenomena is consistent enough to be falsifiable. A technology becomes culturally dominant when it satisfies three conditions simultaneously: an engagement loop that captures attention, network effects that compound value as adoption rises, and a clear path to monetisation. The internet on its own satisfied two of the three. The internet on the iPhone satisfied all three, and the cultural revolution that followed was the result.

AI in its current form, foundation models accessed through chat interfaces, satisfies one or two of the three. Foundation-model companies have (still to be proven at scale) monetization , weak network effects, and largely utilitarian rather than addictive use. Anthropic and OpenAI are fundamentally building infrastructure businesses, with the engagement loops as a secondary consideration. That may become a profitable category but not the category that becomes the dominant cultural force. Where AI satisfies all three is the application layer that Tristan Harris has begun calling the attachment economy: AI companions, AI relationships, embedded AI tutors, AI confidants [8]. Engagement loops, in their most direct form, the relationship-attachment kind, run a subscription clock that does not stop. Network effects emerge as the AI accumulates context about its user and the user invites the relationship into shared spaces. Monetisation is the subscription itself, plus the data, plus the ecosystem lock-in. All three conditions, in the same product category. Replika is the early version. Character.ai is another. Most of the specific companies in this space will not survive in their current form. The category they sit inside almost certainly will.
The practical test follows from the framework. When you read about a new AI product in 2026, ask three questions: does it create an engagement loop, does it benefit from network effects, does it have a clear monetisation path. If the answer is yes to all three, you are looking at a candidate Y. If the answer is yes to one or two, you are looking at infrastructure. The current investment debate is almost entirely focused on infrastructure. The category that almost nobody is arguing about, because it still sounds small from inside the 2026 vocabulary, is where the cultural and economic centre of the AI era almost certainly forms. The closest a careful reader can get to the actual unforeseen Y is to look at which technology is starting to satisfy all three conditions, and to take that category more seriously than the infrastructure debate currently does.
The 2025 divergence
The unforeseen Y is already partly observable, and the data are starting to fill in.
US GDP grew 2.7% in 2025. Net employment over the same year was 181,000 jobs added, the worst figure for any non-recession year of expansion since 2003 [4]. Bloomberg published a piece in February 2026 under the headline Unprecedented “Jobless Boom” Tests Limits of US GDP Expansion, and the accompanying chart showed real GDP and nonfarm payrolls (two lines that moved in near-lockstep for over three decades) diverging in a way that, in Bloomberg’s words, “has never happened this far into expansion” [4]. What makes the configuration anomalous is that this is not a recession picture. There is no economic contraction holding payrolls down. The expansion is real, and it is happening without the headcount that used to come with it.
The killer specific is the per-employee revenue stat. In fiscal year 2024, Salesforce, by some distance the most successful pure-software company of the last decade, generated nearly thirty-five billion dollars of revenue with around seventy-three thousand employees, which is roughly half a million dollars of revenue per worker, strong by any pre-AI software standard. Two years later, Anthropic is producing roughly thirty billion dollars of revenue at an annualised run rate, with around three and a half thousand employees, which is closer to eight and a half million dollars of revenue per worker. Same software industry, same broad addressable market, two years apart. Salesforce has roughly twenty times the headcount producing nearly the same revenue, and the per-worker output at the AI-native firm is around eighteen times what Salesforce achieved at peak [5]. Put another way: if Salesforce in 2024 had operated at Anthropic’s 2026 per-worker productivity, it would have employed about four thousand people. The remaining sixty-nine thousand jobs were not, by any 2024 measure, redundant. They were the standard cost of running a company. The economy underneath that comparison is one in which output and employment are decoupling at the company level for any firm willing to build around the new tooling.

Beyond the macro charts, the pattern is showing up at named-CEO level. Klarna disclosed in early 2024 that an AI assistant was doing the work of around seven hundred customer-service agents, and the company’s headcount fell from roughly five thousand to three and a half thousand over the following year while revenue rose. Duolingo’s chief executive said in January 2024 that around ten per cent of the company’s contractors had been let go because AI was now doing their work. Goldman Sachs has visibly compressed junior banking-analyst hiring through 2025, with multiple reports of cohort sizes shrinking and some entry-level functions being routed through AI tooling instead [6]. None of these is a layoff event in the conventional sense. They are quiet adjustments to the production function, and they accumulate.
What macroeconomists have been arguing should not happen this far into an expansion is happening. The production function underneath the headline numbers has changed, and the change is showing up in the GDP-versus-payrolls chart, in the per-employee revenue gap, and in a steady drumbeat of named-CEO disclosures that AI is now doing work the company used to staff for. The first-order story (AI substitutes for cognitive labour at speed X) is one frame. The second-order story (the relationship between economic output and human employment is being rewritten in real time) is plausibly bigger, and is happening regardless of whether you believe the first-order story or not.
The political response to the divergence is already visible. New York elected Zohran Mamdani as mayor in November 2025 in part because, as Dror Poleg observed, voters experienced the divergence firsthand: the economy was growing, the stock market was soaring, and yet their material lives were not getting better [7]. San Francisco, in the same season, elected a different sort of mayor and started liberalising zoning. Two cities, two different responses, both confirming that the structural break is real and that voters can feel it before economists are willing to call it.
A short personal note
I’ve spent thirty years in finance, which is one of the sectors most exposed to the noise mechanism I’ve just described, and I read for a living the kind of analysis that AI now produces in volume. The best calibration of any thesis I write on AI’s impact is to remember that I’m squarely inside the affected slice and probably overweighting my own experience by a margin I cannot quite measure.
I have tried to write this article under a new format where it should be easier to capture the subject of the post from the very beginning and also provide a summary at the end. If you like this new format please “like” the post, it means a lot to me.
Bottom Line
In 1995, the case for the internet was that it would let us work and consume more efficiently. It did, eventually, in that narrow sense. The bigger story took twelve more years to arrive, and arrived through a device nobody in 1995 had thought about: the iPhone, which made the always-on internet into a pocket-sized reality and turned social media from a niche curiosity into the dominant capture mechanism for human attention. The unforeseen Y, in retrospect, was not the internet at all. It was the smartphone.
The case for AI today reads almost identically to the 1995 case for the internet. The first-order story is well-understood and being argued about in every research note and every Substack. It is also, probably, not the story that will matter most in retrospect. Whatever the dominant impact of AI turns out to be, it is almost certainly not on anyone’s spreadsheet right now. Watch for what is being built with all this capability that nobody designed for. The next piece in this AI series asks the question that follows: when noise dominates, where does signal go, and who pays for it?
References
[1] American Federation of Musicians, Music Defense League records, 1930. The 22,000 jobs lost figure is the AFM’s own contemporaneous estimate of theatre-musician unemployment by 1930, and is the canonical historical record cited across the labour-history literature on the talkies transition. The campaign and its underlying figures were widely covered at the time, including in Smithsonian Magazine‘s retrospective on the Music Defense League.
[2] Dror Poleg, Who Will Get Canned in 2026?, drorpoleg.com, 30 December 2025. The “disruptive technology rarely seeks to replicate; it sidesteps and makes the old standards redundant” framing in Section 2 is Poleg’s, and the article’s reading of the talkies episode owes its shape to his piece.
[3] Bart Hobijn and Boyan Jovanovic, The Information Technology Revolution and the Stock Market: Evidence, NBER Working Paper No. 7684, May 2000. Assumption 2 of the model records the 1973 consensus that IT would substitute for white-collar cognitive labour the way mechanisation had substituted for blue-collar.
[4] Unprecedented “Jobless Boom” Tests Limits of US GDP Expansion, Bloomberg, 18 February 2026. The chart of real GDP versus nonfarm payrolls and the “never happened this far into expansion” framing are drawn from this piece. The 2025 GDP growth of 2.7% and the 181,000 jobs added (worst non-recession year since 2003) are from US Bureau of Labor Statistics Employment Situation reports and Bureau of Economic Analysis NIPA tables, both publicly available.
[5] Anthropic annualised revenue run-rate of approximately thirty billion dollars as of April 2026, and headcount of approximately three and a half thousand, reported by Reuters and Bloomberg, April 2026. Salesforce fiscal-year 2024 revenue of $34.86 billion and year-end employee count of 72,682, per Salesforce’s audited 10-K filing, February 2024.
[6] Klarna headcount and AI-customer-service disclosure: public statements by CEO Sebastian Siemiatkowski via X and Bloomberg interviews, 2024-2025. Duolingo contractor reduction: public statement by CEO Luis von Ahn, January 2024 earnings communications. Goldman Sachs junior banking-analyst hiring compression: multiple Bloomberg and Financial Times reports through 2025.
[7] Dror Poleg, Welcome to the Jobless Boom, drorpoleg.com, 18 February 2026. The Mamdani-divergence interpretation cited in the 2025 divergence section is from this essay.
[8] Tristan Harris, Center for Humane Technology. The “attachment economy” framing extends the engagement-economy critique of social media to AI specifically, with AI companions and AI-mediated relationships as the central category. From Harris’s recent public appearances and writings.
[9] Stray Narratives, Issue 06: The Noise Economy, 12 April 2026. The friction-elimination argument with the 13% / 77% workforce split is developed in this issue.